
機械学習を始める方へ おすすめの書籍
貴子藤井
機械学習の始め方

機械学習で一番とっつきやすい 教師あり学習について説明します
入力データに対して 答えとなるデータを出力する状況で使われます
例えば、画像に写っているものが何かを当てるシステム、
メールの文面から迷惑メールと そうでないメールを分類するシステム、
気温や天候から商品の需要を推定するシステム などがあります

教師あり学習とはまさに人間が勉強をして問題を解けるようになる行為に似ています
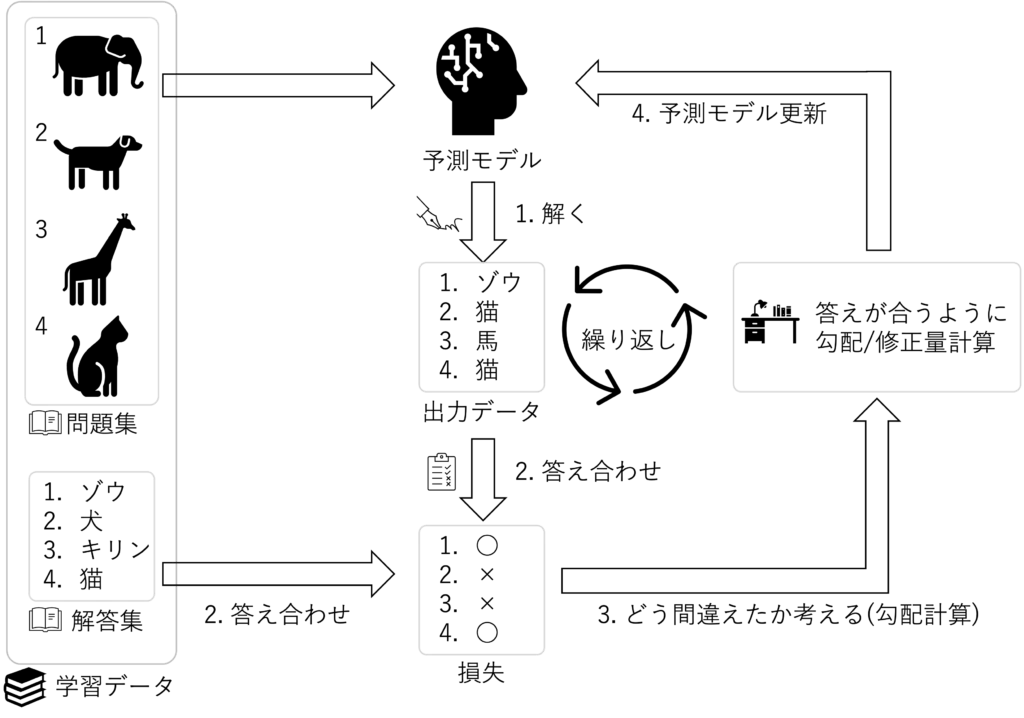
下の図で説明していきます
予測モデルと書かれているところは、最終的にシステムに組み込んで使います
予測モデルを学習させるために、学習データというものが必要となります
学習データは、入力データ(問題集)と正解データ(解答集)のペアで構成されます
下記❶〜❹の流れを繰り返して予測モデルの精度を向上させることを狙います
まさに人間が問題集を何度も解いて、正解の数を増やしていくことに似ています
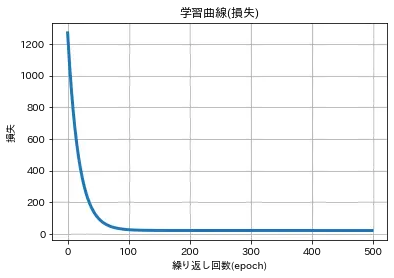
下の図はある問題を繰り返し学習したときの 間違いの大きさを表す学習曲線というグラフになります
横軸は学習の繰り返し回数を表し、縦軸は間違いの大きさを表す損失になってます
学習の最初は1200を超える損失となってますが 100回を超えたあたりから0に近い値となっていることがわかります
機械学習でよく使われる言葉として学習の繰り返し回数のことをエポック(epoch)といいます
教師あり学習は さらに回帰と分類に分けることができます
回帰の問題は最初に出した例でいうと需要予測システムが挙げられます
大きな特徴は、出力が連続値となることです
例えば、下の図は 気温とアイスクリームの売り上げを予測モデルで表現したものです
0度の時の売り上げが予想でき、その時の仕入れ量を決めるのに役立ちます
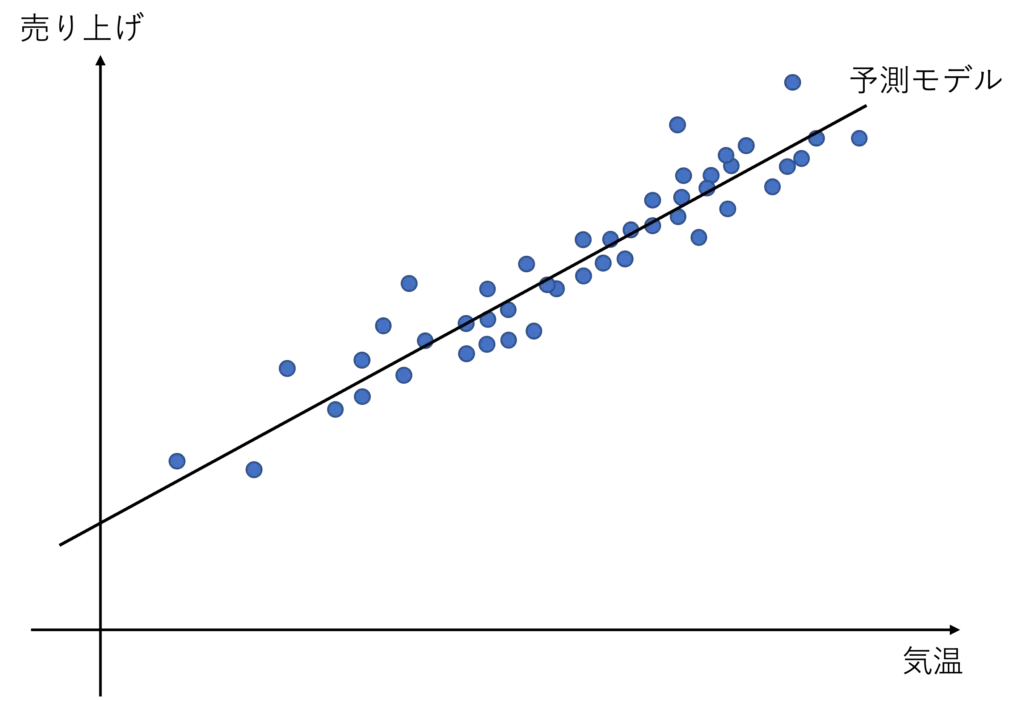
この例では気温とアイスクリームの売り上げの関係性が分かりやすいですが、
大量のパラメータがある場合、関係あるのかないのかわからない項目・パラメータ選びも
大切になってきます
重要なパラメータを抽出するような場合も、機械学習の範囲で行うことがあります
分類問題は最初の例で言うと画像認識やメールの振り分けになります
回帰問題との大きな違いは、出力が離散になるということです
画像認識ではゾウ、猫などの値をとり、メール振り分けでは通常 or 迷惑フォルダに仕分けることになります
特にメールの振り分けは通常フォルダと迷惑フォルダのどちらか2つの値を取るので2値分類といわれます
3種類以上の分類を行うことは多値分類というカテゴリに分けられます
分類問題ではゾウや猫などの正解が離散値になるので、そのままでは どれくらい間違っているかを評価することができません
そこで答えの自信度として確率を使っていきます
下の図では、最も確率が大きいゾウが答えとなります
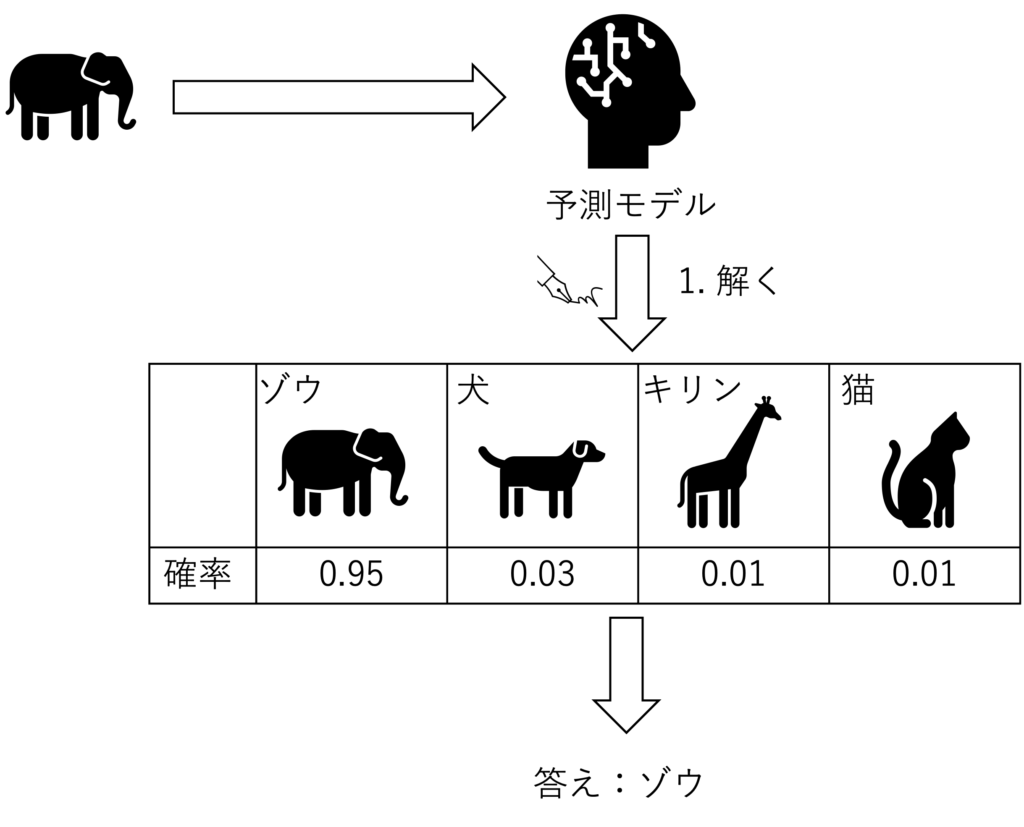
また、回帰問題と違って分類問題は、予測した結果が正解か否かを判定することができます
正解率を精度として評価を行っていきます
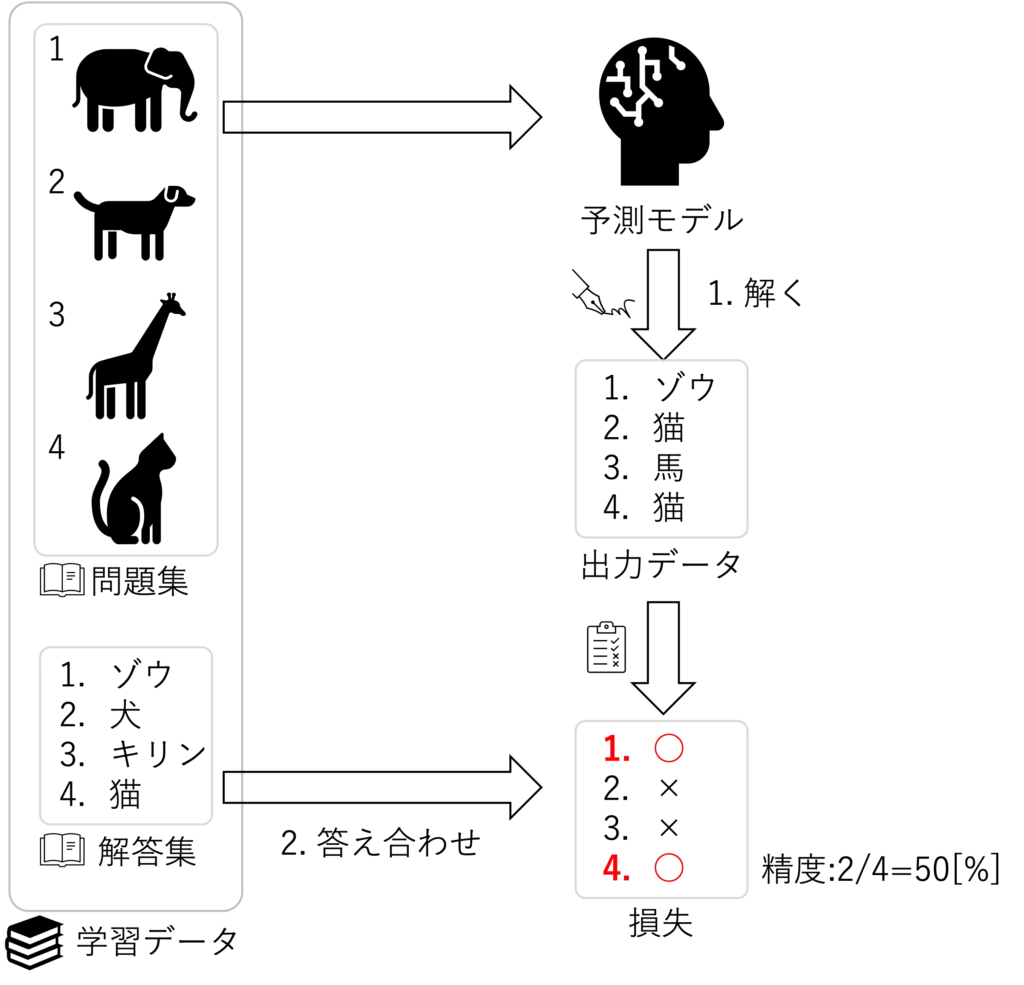
上の図の例で言うと予測モデルの精度は50%と言うことになります
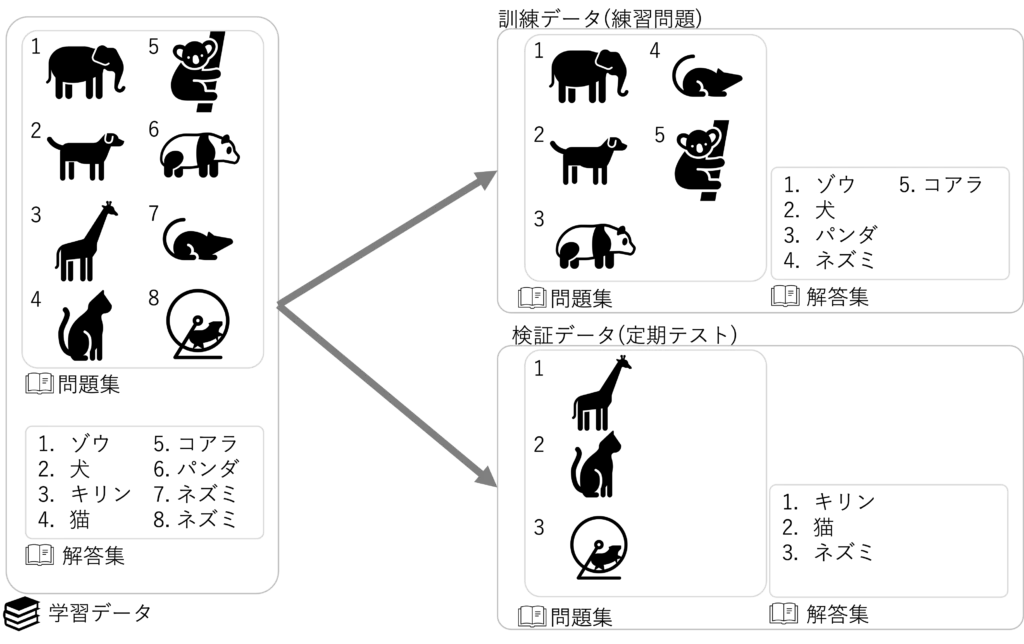
分類問題では学習データを訓練データと検証データの2つに分けて、予測モデルの学習や評価を行います
訓練データは、勉強で言うところの練習問題に相当し、予測モデルの学習用データとして使用します
検証データは、実力テストのように実力を測ることに相当し、予測モデルの評価用データとして使用します
訓練データと検証データは、同じデータは使わずに分けておきます
学習データで解けた問題の解き方が、検証データでも通用するのか という確認に使うので
同じ問題だと正しい評価ができないためです
下の学習曲線のように訓練データではうまく学習が進んで、損失・精度とも上がっている状況なのに、検証データでは精度が上がらない状況を過学習といいます
勉強で言うところの練習問題はできるけど、実力テストが解けない状況ですね
丸暗記や練習問題に特化した解き方のみで、実際の応用問題などが解けない状況に似ています
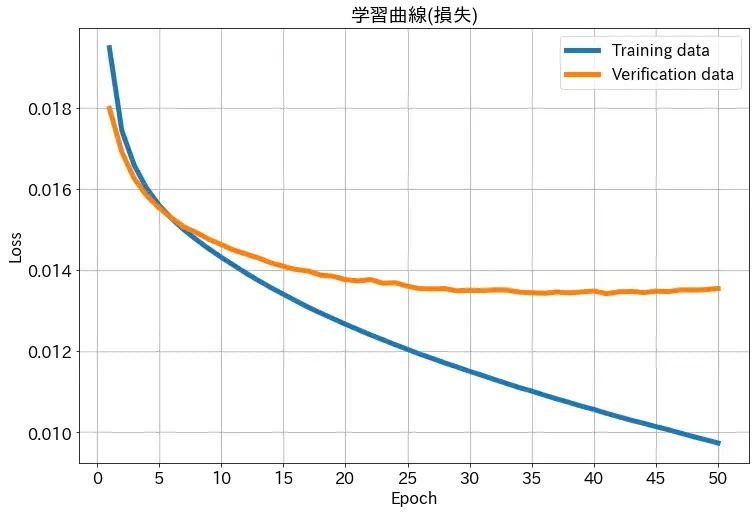
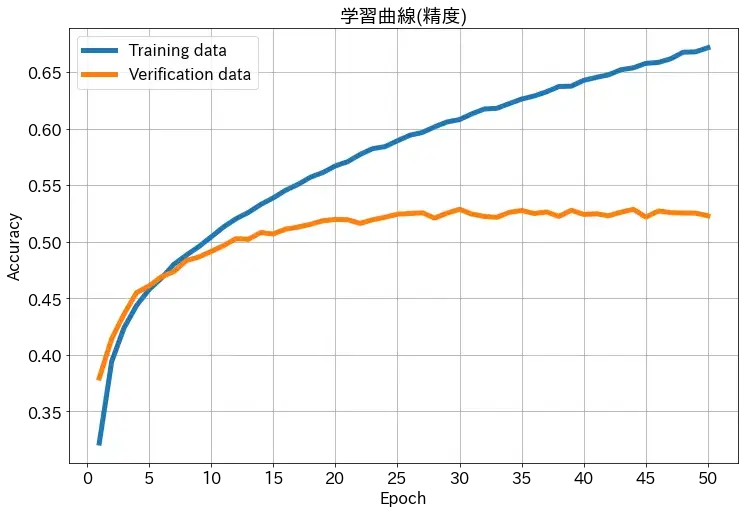
上の図の例では、あるデータを50回繰り返し学習させた時の訓練/検証データの損失と精度のグラフになります
損失のグラフでは学習回数10回くらいまでは、訓練/検証データのどちらも順調に損失が降下していることがわかります
しかし、検証データは学習回数10回以降、降下が鈍化して1.4を少し下回るくらいで停滞していることがわかります
同様に、精度のグラフでも同じようなことが言えます
訓練データでは順調に精度は上がっていき、最終的には65%以上の精度になっています
一方、検証データでの精度は、最終的には50%程度にとどまっています
機械学習の世界では、予測モデルが未知のデータを正しく識別する能力を汎化性能・汎化能力
といいます
下図のように、機械学習には学習フェーズと推論フェーズの2つが存在します
予測モデルを学習する環境(学習フェーズ)と
実際に予測結果を出力して活用する環境(推論フェーズ)が異なる場合があります
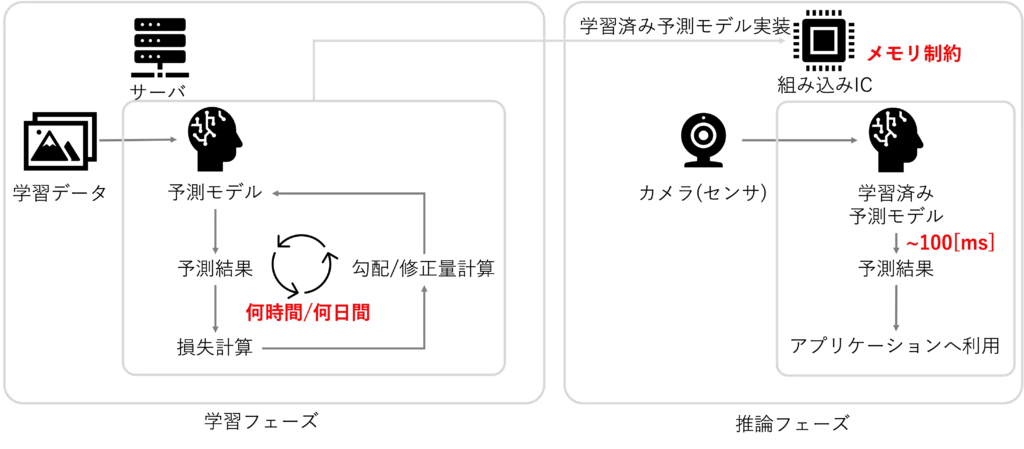
一般的に学習を繰り返し行う場合、かなりの計算量になります
GPUが積まれたサーバ環境などでも、学習には数時間〜数日かかることは よくあります
特にスマホや自動車・家電に組み込まれているような ICで学習をすることは
現実的ではありません
通常は、あらかじめ学習した予測モデルを 組み込み系のICにインストールして使用します
その際にも、組み込み系の制約として 搭載されているメモリ量が潤沢でなかったり、
予測結果にリアルタイム性が必要だけど、CPUのパワーに制約があったりします
そのような制約下でも動作するように、予測モデルには軽量であることが求められる場合が
多いです
最後に教師あり機械学習のおすすめ書籍を紹介します
最短コースでわかる ディープラーニングの数学
教師あり機械学習の数学的な知識と数式を、Pythonプログラムで紐づける形で丁寧に説明がされています
高校数学の復習からスタートしているので初学者にも とっつきやすいかと思います
最短コースでわかる PyTorch &深層学習プログラミング
ひとつ前の続編にあたる書籍で、ディープラーニングのPythonライブラリであるPytorchを用いて、教師あり機械学習の全体像を理解することができます
どちらの書籍もGoogle Colabを使っての実装になりますので、PCがあれば実行できますし
大変おすすめです


