
PyTorchで学ぶディープラーニング:はじめてのニューラルネットワーク構築
s.fujii0909
機械学習の始め方

この記事では、Pytorchを使用した画像分類についてハンズオン形式で解説します
以前紹介したPytorchの簡単な分類問題の説明は下記ページにありますので、まだ見ていない方はよろしければご一読ください

今回は、画像分類の問題で使われている畳み込みニューラルネットワーク(CNN)について、
説明します
CNNには下記のような4つの特徴があります
ざっくりいうと、画像上の輪郭などのエッジに含まれる情報をうまく使うために、画像上の周囲の情報をうまく使う仕組みです
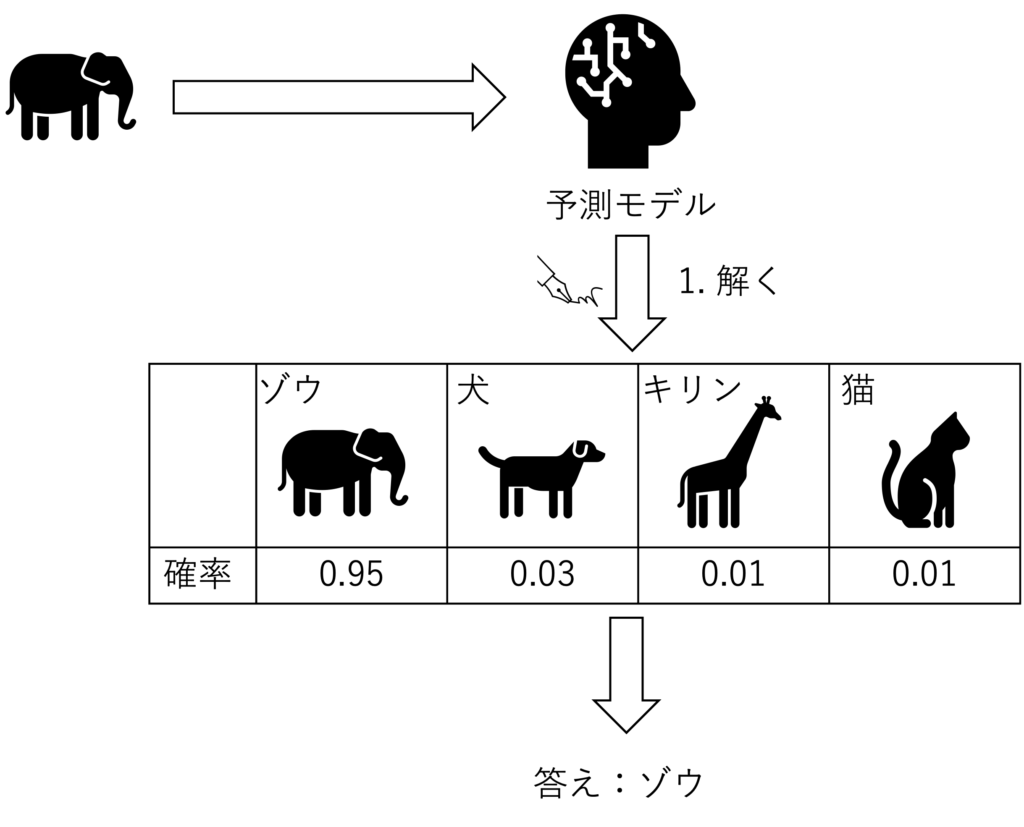
画像の分類、特に顔画像から誰なのかを解くモデルの構築を目指します
下記のようにゾウの画像を予測モデルに入力したときに、ゾウ、犬、キリン、猫の中から答えを探す問題となります
今回はあらかじめ準備されている画像データセットを使おうと思います
PyTorchには、PyTorchVisionという標準的なデータセットや 様々な予測モデル、便利な関数がいくつも準備されています
PyTorchVisionについてと、その中で使うデータセットについて紹介します
PyTorchにはPyTorchVisionというサブプロジェクトがあり、簡単に画像処理タスクを実装できるように設計されています
PyTorchVisionは下記のような便利な機能が実装されています

今回は顔の分類を行うので、顔画像が収録されているLFWを使おうと思います
LFW(Labeled Faces in the Wild)は、PyTorchVisionが提供するデータセットの1つで、13,000枚以上の顔画像が含まれています
これらの画像は、主にインターネット上から収集されたもので、さまざまな背景、照明条件、
表情、ポーズのもとで撮影されています
下の画像はLFWから取得したデータをグリッド上に表示したものになります

今回は画像分類を行うためのCNNを実装します
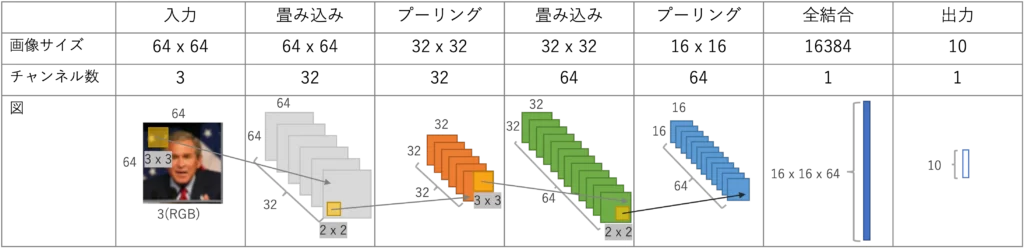
構築するCNNは、下記のような入出力を持つネットワークになります
入力:64 x 64ピクセルのカラー画像
中間:畳み込みとプーリング層で画像の特徴を抽出
出力:あらかじめ決めた10人の中の誰なのか
中間の畳み込み層、プーリング層などの配置数やチャンネル数などは 様々に設計できますが、
入力と出力の辻褄が合うようにする必要があります
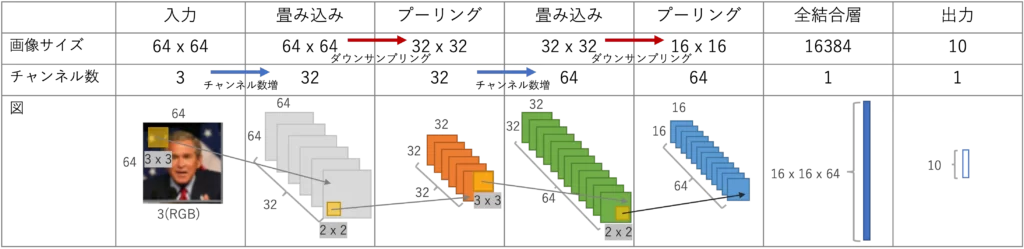
今回構築するネットワークは下記の通りです
まずは、CNNで使われる畳み込み、プーリングに合わせて活性化、全結合についても説明します
畳み込みは、画像の局所的な特徴を抽出するために用いられる演算です
畳み込み層では、カーネル(またはフィルタ)と呼ばれる小さなウィンドウが
入力画像上をスライドし、そのウィンドウ内のピクセルとカーネルの要素の積和を計算します
この操作によって、画像のエッジやテクスチャなどの特徴が検出されます
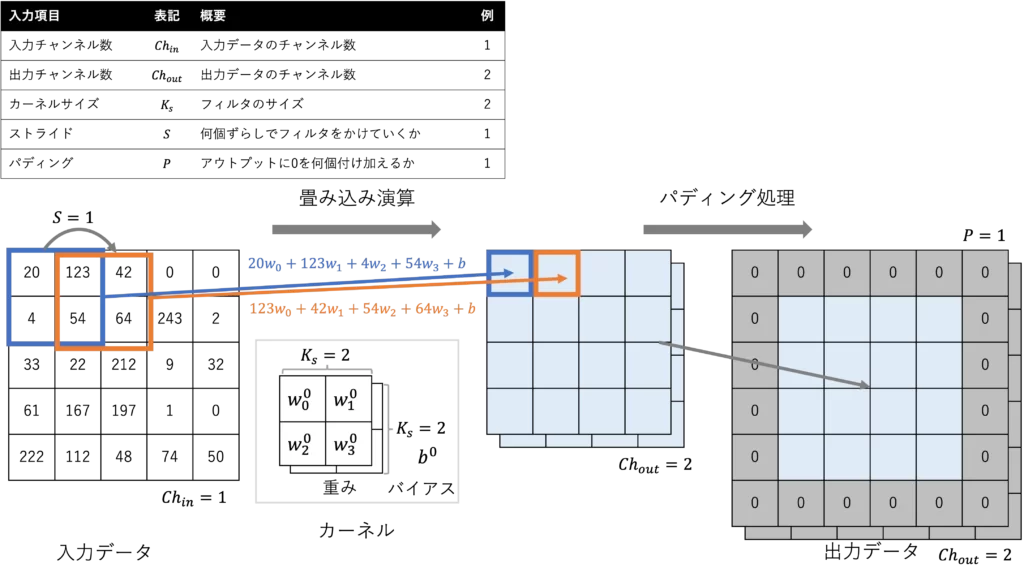
下の図で簡単に説明します
畳み込みフィルタには、入出力のチャンネル数、カーネルサイズ、ストライドとパディングを
入力して計算をします
畳み込み演算
入力データに対して、フィルタの積和演算とバイアス項を加えたものを出力します
次の演算ではフィルタをストライド分ずらしていき、上記の演算を繰り返します
入出力のチャンネル数分だけフィルタもあり、繰り返し演算を行なっていきます
畳み込み演算では、チャンネル数を増やすことが一般的で、特徴量を抽出していくように
フィルタの重み、バイアスが学習をしていくことになります
パディング処理
畳み込み演算をすると、出力するデータは入力データより小さくなってしまいます
パディング処理は 出力データが小さくなって、特徴量がなくならないように
データの外側を埋める処理になります
下図では 入力データと出力データのサイズが一致していませんが、カーネルサイズを奇数にすれば、入出力のサイズを一致させることができます
torch.nn.Conv2d()で実装していきます
PyTorch公式ドキュメント
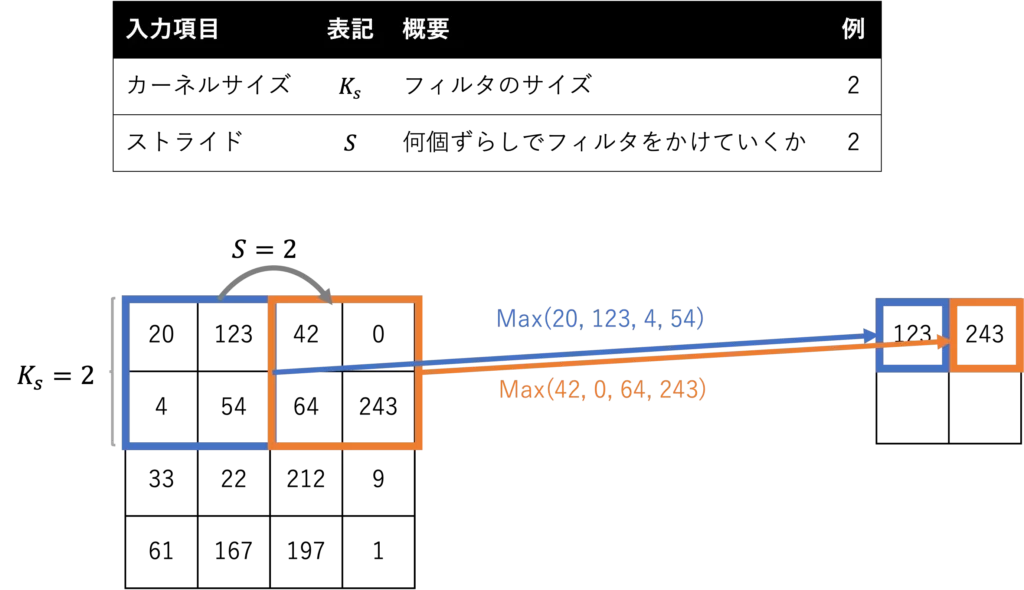
プーリングは、畳み込み層で抽出された特徴マップを ダウンサンプリングすることで、
画像の空間サイズを縮小し、計算量を削減します
また、プーリングによりネットワークは位置に対する不変性が向上し、過学習を防ぐ効果もあります
一般的なプーリング手法には、最大プーリング(Max Pooling)と平均プーリング(Average Pooling)がありますが、大体の場合は 最大プーリングが使われていることが多いような気がします
torch.nn.MaxPool2d()で実装します
PyTorch公式ドキュメント
活性化関数は、ニューラルネットワークに非線形性を導入するために使用されます
CNNの場合は畳み込み層の後に挿入されることが多いです
活性化関数を適用することで、ネットワークは より複雑な関数やパターンを学習できるようになります
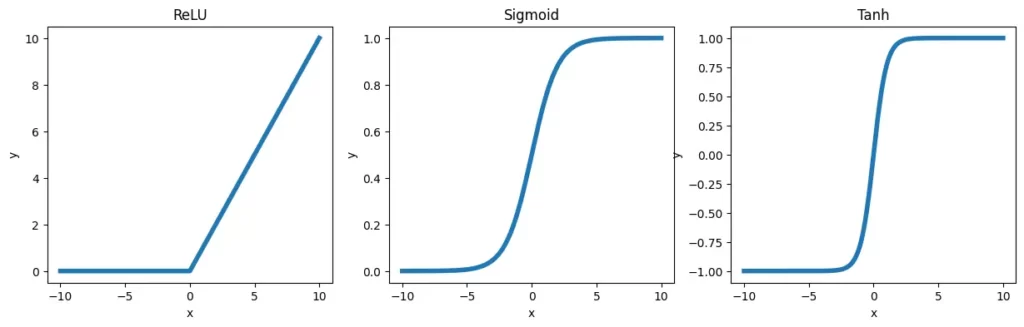
一般的な活性化関数には、ReLU関数(Rectified Linear Unit)、シグモイド関数(Sigmoid function)、ハイパボリックタンジェント関数(Tanh function)などがあります
ReLU関数は、現在 最も一般的に使用される活性化関数で、負の入力値に対して0を出力し、
正の入力値に対しては そのままの値を出力します
下記がそれぞれの活性化関数のグラフになります
torch.nn.ReLU()で実装します
PyTorch公式ドキュメント
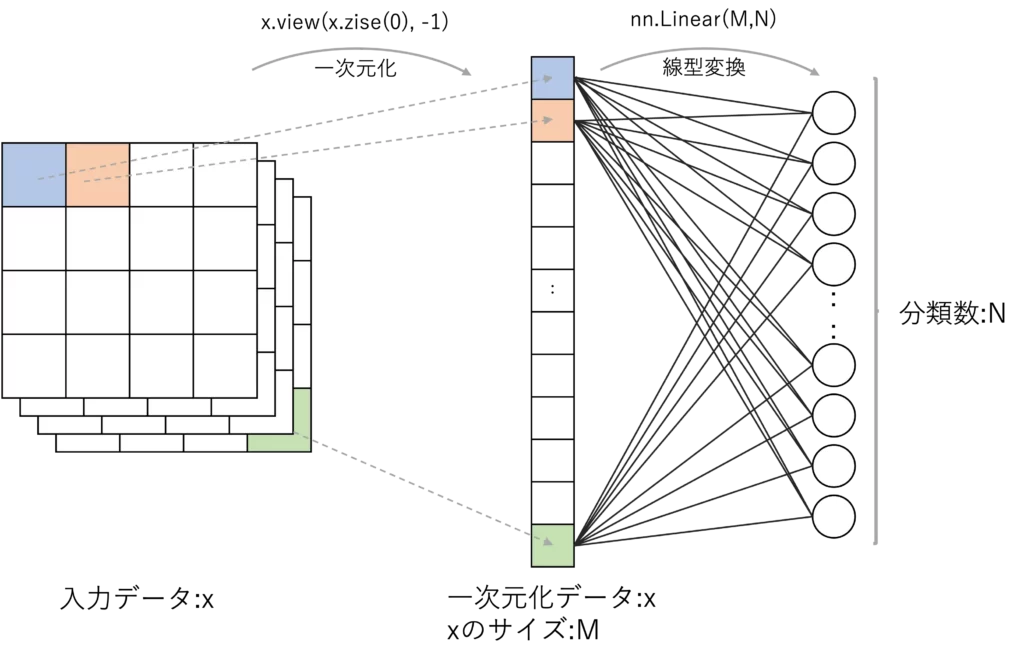
全結合層は、畳み込み層やプーリング層で抽出された特徴を用いて、最終的な分類を行います
全結合層では、入力ユニットと出力ユニットが すべて接続されており、特徴が一次元のベクトルとして扱われます
全結合層は通常、ネットワークの最後の部分に配置され、出力ユニットの数は 分類するクラス数と同じになります
最終的な出力で値が大きいものが、モデルの答えになります
実装はx.view(x.size(0), -1)とnn.Linear()で実現します
torch.Tensor.view(): 公式ドキュメント
nn.Linear(): 公式ドキュメント
ここまで、畳み込みやプーリングについて見てきました
畳み込み層では、注目画素の周囲の特徴量を含めてフィルタを学習していきます
その際に特徴量を多く残すため、チャンネル数を増やします
逆にプーリング層では、特徴となる値を残しつつ データ量を削減するダウンサンプリングを行なっています
このようにCNNでは、畳み込み層とプーリング層で画像の特徴を多く抽出しつつ、データ量を抑える仕組みになっています
下図にその様子を示しています
今回は画像分類によく使われているCNNについて解説をしました
次回は構築したCNNの実装について紹介をしていきたいと思います



