
機械学習を始める方へ おすすめの書籍
貴子藤井
機械学習の始め方

今回は、前回紹介した 画像分類のためのCNN構築 – PyTorchでの実装方法について紹介します
概要編は下記にありますので、まだ見られていない方は 良かったらご覧ください

簡単に 前回のおさらいと、問題設定の詳細化をしておきます
顔画像から誰なのかを分類する問題を考えます
PyTorchVisionでダウンロードできる LFWという顔画像が収録されているデータセットを使用します
下記のような画像が、5000枚以上入ってます

中身を見ていくと ほとんどの人が 1人1枚づつの写真しか入っておらず、これでは 学習と検証データを分けることができません
そこで、できるだけ多くの写真が収録されている人物を 抽出することにします
同じ人物が写っている枚数順に、上位10名を抜き出して、その顔画像の分類をしていきます
画像分類するための予測モデルとして下記のCNNを実装してみたいと思います
畳み込み層、プーリング層を2つずつあり、最後に全結合層で分類結果の出力を行います
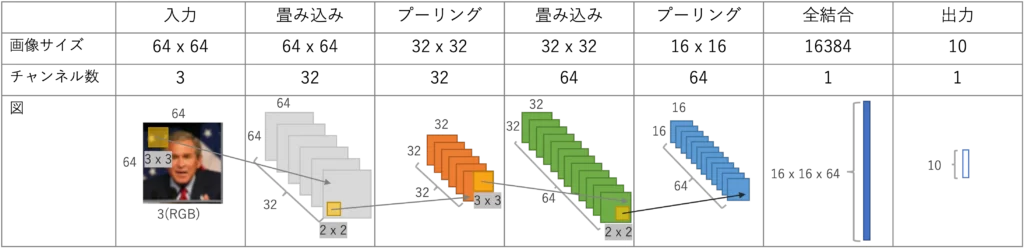
では早速、PyTorchによる実装の説明をしていきます
Google Colabでも実行できると思います
実装の説明に入る前に、全体像の把握をした方が 理解が早まると思います
# 必要なライブラリをインポート
import collections # ラベルの頻出頻度を調べる
import torch # PyTorch全般
import torch.nn as nn # ネットワークの構築
import torch.optim as optim # 学習の最適化を
from torch.utils.data import DataLoader # データを効率よく呼び出す
import torchvision.transforms as transforms # 画像の正規化などの前処理
import torchvision.utils as utils # 画像表示用のユーティリティ
from torchvision.datasets import LFWPeople # LFWデータセット
import matplotlib.pylab as plt # データのプロット
import numpy as np # 画像配列を数値配列として扱うこの後に続く ライブラリのインポートをしています
簡単に説明をします
collections :
データの出現頻度を調べるために collections.Counter() というクラスを用いてます["A", "B", "C", "A", "A", "C"]のようなリストがあった場合にAの個数を調べたり、出現頻度を多い順に並べるときに便利なライブラリになります
torch :
Pytorchを使用するのに、必要なものを読み込んでいます
torch.nn : ネットワークを構築したり、損失関数の定義に必要なライブラリです
torch.optim : 学習をする際の最適化関数を定義します
from torch.utils.data import DataLoader : 学習データをシャッフルしたり、ミニバッチ学習のバッチ毎にデータを分けるための便利なクラスになります
下記にPyTorchの簡単な例を載せてます

torchvision:
PyTorchVisionを使用するのに必要なものを読み込んでいます
torchvision.transforms : 画像のリサイズ や PyTorchをテンソル型に変換する前処理に使用します
import torchvision.utils : データセットの画像を格子状に並べるためのユーテリティ関数として使用します
from torchvision.datasets import LFWPeople : LFWのデータセットをダウンロードするために使用します
matplotlib:
matplotlib.pylab : 画像・データの可視化をするためのライブラリです
numpy:
行列計算などの汎用数値解析ライブラリです
PyTorchのテンソル型では、matplotlibではプロットできないので、一度numpy型にしています
PyTorchのバージョンの確認とプログラムの再現性を持たせるために乱数の初期化を行います
print(torch.__version__)
torch.manual_seed(0)出力結果
2.0.0
画像データを処理するときに、PyTorchで扱いやすくするための前処理を定義しますtransforms.Compose() を使うと、一括でさまざまで画像変換を行うことができますResize((64, 64))で画像のサイズを64ピクセルに変換、ToTensor() でPyTorchのテンソル型へ変換、Normalize(mean, std)で、出力=(入力-mean) / stdの変換を施しています
テンソルの各要素から指定した平均値を引き、指定した標準偏差で割る操作を行います
具体的な式は以下の通りです
正規化後の値 = (元の値 - 平均) / 標準偏差ToTensor() により画像の各ピクセル値が、0.0から1.0の範囲にスケーリングされています
したがって、RGBの各チャンネルの平均は0.5、標準偏差も0.5です
このため、正規化後の値は以下のように計算されます
正規化後の値 = (元の値 - 0.5) / 0.5 = 2*元の値 - 1他にも、学習時のデータ数水増しのための変換関数なども準備されていますので必要に応じて公式ドキュメントを参照してください
transform = transforms.Compose([
transforms.Resize((64, 64)), # 画像のリサイズ
transforms.ToTensor(), # PyTorchのテンソル形式へ変換
transforms.Normalize(mean=(0.5, 0.5, 0.5),
std=(0.5, 0.5, 0.5)) # RGB各チャンネルの平均・標準偏差を正規化
])現在のソースコードを置いている場所に、data というディレクトリ(フォルダ)を作成してください
下記コードで LFWのデータを取得します
lfw_dataset = LFWPeople(root='./data', download=True, transform=transform)この関数は、lfw_dataset にLFWのデータセットを格納します
場所はdataディレクトリを参照し、なければダウンロードを行います
240[MB]ほどのデータをダウンロードします
また、先ほど定義した前処理transformsも このタイミングで行います
lfw_datasetの中身は、ざっくり下記のような構成になっています
lfw_dataset[0]を読み出すと配列とラベルの対のリストが得られると思います

LFWデータセットには、5000名以上の画像が入っています
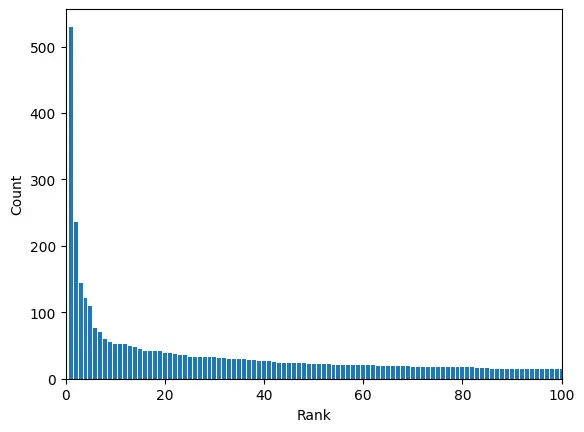
データセットの中の出現頻度トップ100を抜き出すと、下記のようになります
今回は簡単にするため、トップ10を抜き出して その画像分類を行うことにします
# データセットからラベルの抜き出し
label_list = lfw_dataset.targets
print(label_list[:10]) # データ確認のため最初の10個表示
# ラベルの出現頻度別に(ラベル, 出現数)で抜き出し
label_counter = collections.Counter(label_list)
freq_list = label_counter.most_common()
print(freq_list[:10]) # データ確認のため最初の10個表示
# 上位num_classes分のラベルを抜き出し
num_classes = 10
top_freq_label = [label for label, _ in freq_list[:num_classes]] # リストの最初にラベルが入っている
print(top_freq_label)
# ラベルを0から採番し直す
# トップ10に入っている画像と採番し直したラベルを新たなデータセットに格納する
label_mapping = {label: i for i, label in enumerate(top_freq_label)}
top_freq_lfw_dataset = [(img, label_mapping[label]) for img, label in lfw_dataset if label in top_freq_label]lfw_dataset.targetsは、データセットに格納されているラベルのみをリストで返します
出力結果
[12, 16, 25, 25, 25, 25, 49, 53, 57, 79]
2つ目のブロックのは、collectionsを使ってラベルの頻出頻度順に並べ替えていますmost_common() は、頻出順にソートして ラベルの出現回数を返してくれます
下の出力結果は、1871 のラベルが 530回出てきたことを意味しています
出力結果
[(1871, 530), (1047, 236), (5458, 144), (1404, 121), (1892, 109), (373, 77), (2175, 71), (2941, 60), (2468, 55), (2682, 53)]
次のブロックは、ラベルの出現回数は不要なため、上位10個分のラベルのみを抜き出しています
ラベルのみを抜き出すのに、Pythonの内包表現で実現しています
出力結果
[1871, 1047, 5458, 1404, 1892, 373, 2175, 2941, 2468, 2682]
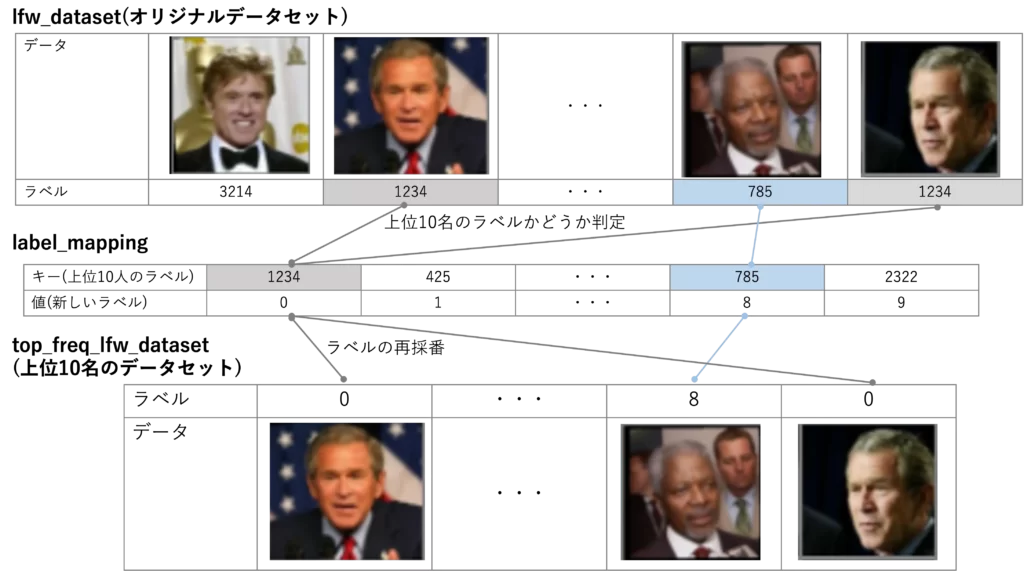
最後のブロックは、データセットから上位10名分を抜き出して、新しい画像とラベルのペアにしています
その際に、1871などのラベルを 0番目から再度採番しなおしています
ラベルを0から順に振っておいた方が、ネットワークの出力と 1 対 1 対応が取れるので便利です
上位データの抽出とラベルの採番の概念図を下図に示します
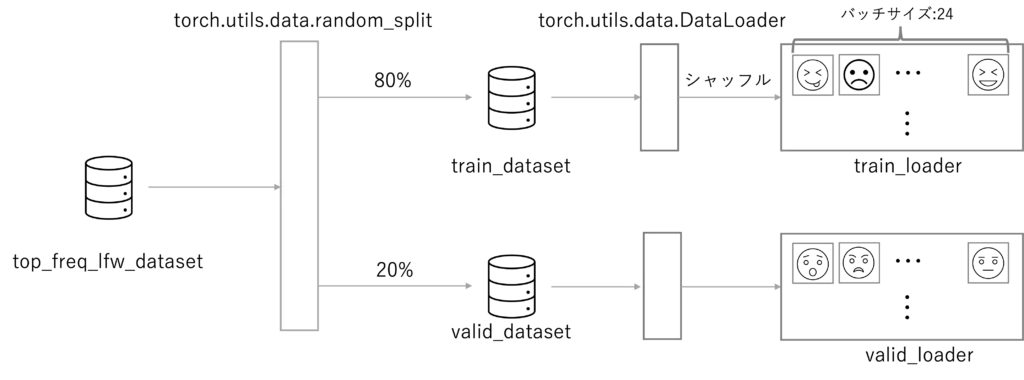
次に、抽出したデータを 予測モデルの学習用データと検証用データに分割をします
さらにデータローダでミニバッチというグループに分けて、学習・検証を行いやすくします
# ハイパーパラメータの定義
batch_size = 24
# データセットを学習データセットと検証データセットに分類する
train_size = int(0.8 * len(top_freq_lfw_dataset))
valid_size = len(top_freq_lfw_dataset) - train_size
train_dataset, valid_dataset = torch.utils.data.random_split(top_freq_lfw_dataset, [train_size, valid_size])
# データローダの作成
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=batch_size, shuffle=False, num_workers=2)上の最初の行で出てくるbatch_sizeは、ミニバッチのサイズです
24に設定しているので 24枚の画像ごとにバッチを分けています
次のブロックでは、データセットの8割を学習データとして、残りの2割を検証データとして扱うことを表していますtorch.utils.data.random_splitは元のデータセットは学習データセットに8割、検証データセット2割に分割する関数です
最後のブロックは、バッチサイズ毎に取り出せるように DataLoaderにセットしています
下記のようなイメージです
次は、データローダに格納した画像データを表示してみましょう
まずは、画像を表示するための表示用の関数を準備します
下記のコードの最初の変換は、先ほど画像の標準化を行ったため、値の範囲が-1.0から1.0になっています
matplotlibで画像を表示するには、0.0から1.0の範囲にする必要があるので、その変換を行なっていますnp_img = img.numpy()は、matplotlibで扱うためにnumpy形式への変換を行なっています
次に、PyTorchではデータの格納順番を 色チャンネル、画像の高さ、画像の幅の順に扱っていますが、matplotlibで表示を行う場合、画像の幅、高さ、色チャンネルの順に格納する必要があるので、その変換を行なった上で画像の表示を行なっています
def imshow(img):
# matplotlibに合うように正規化の修正
img = img / 2 + 0.5
# matplotlibで出力できるようnumpyへ変換
np_img = img.numpy()
# [C, H, W] -> [H, W, C]に変換して表示
plt.imshow(np.transpose(np_img, (1, 2, 0)))
plt.xticks([]) # X軸の数値を消す
plt.yticks([]) # Y軸の数値を消す
plt.show()続いて、上の表示関数を使って学習用のデータローダ画像を表示します
まず、学習用のデータ数は 24個ずつに分けたので、その最初の一つを取り出しています
画像を表示する際に、TorchVisionの便利関数 make_gridを使うとデータローダの画像を格子状にしてくれるので大変便利です
# 学習用のデータローダの先頭を取り出す
data_iter = iter(train_loader)
images, _ = next(data_iter) # 返り値の2番目はラベルが入っているが描画に使わないのでダミー変数を割り当て
# 画像の表示
imshow(utils.make_grid(images))
いよいよ CNNの実装を行なっていきます
改めて、機械学習のフレームワークでいうところの下記の赤の部分の予測モデルの実装になります
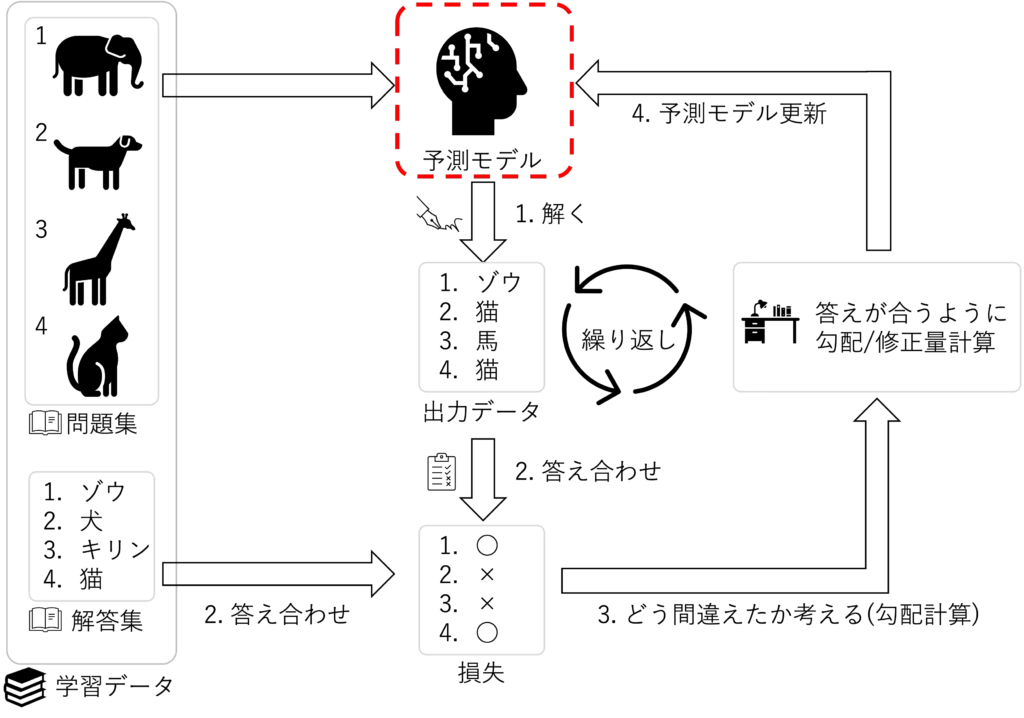
実際に実装するのは下記のCNNになります
上図をPyTorchで実装すると、下記のようになります
コンストラクタで使用している ネットワークの関数について下記の表に簡単にまとめます
上図の設計図が出来ていれば、素直に実装できるようになっています
| 関数名 | 概説 |
| Conv2d( in_channels, out_channels, kernel_size, stride=1, padding=0) | 2次元の畳み込み(公式ドキュメント) in_channnels: 入力チャンネル数 out_channnels: 出力チャンネル数 kernel_size: カーネルサイズ stride: フィルタのステップ数 padding: フィルタ適用後のパディング数 |
| ReLU() | 活性化関数ReLU(公式ドキュメント) |
| MaxPool2d( kernel_size, stride=None, padding=0, ) | Maxプーリング(公式ドキュメント) kernel_size: カーネルサイズ stride: フィルタのステップ数 padding: フィルタ適用後のパディング数 |
| Linear( in_features, out_features, bias=True) | 線型結合(公式ドキュメント) in_features: 入力数 out_features: 出力数 bias: バイアスを持つか否か |
nn.Module の メンバ関数である forwrd() で、コンストラクタで定義した関数を繋げていきます
最後の全結合に行く前に x.view(x.size(0), -1) で、データを一次元にするところ以外は、そのまま直列に繋いでいきます
# CNNモデル定義
class SimpleCNN(nn.Module):
def __init__(self, num_classes):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc = nn.Linear(64 * 16 * 16, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x上で実装した 予測モデルに合わせて、損失と最適化関数を呼び出せるように準備します
下図の 2.答え合わせ・ 3.どう間違えたかを考える・ 4.予測モデル更新 の部分になります
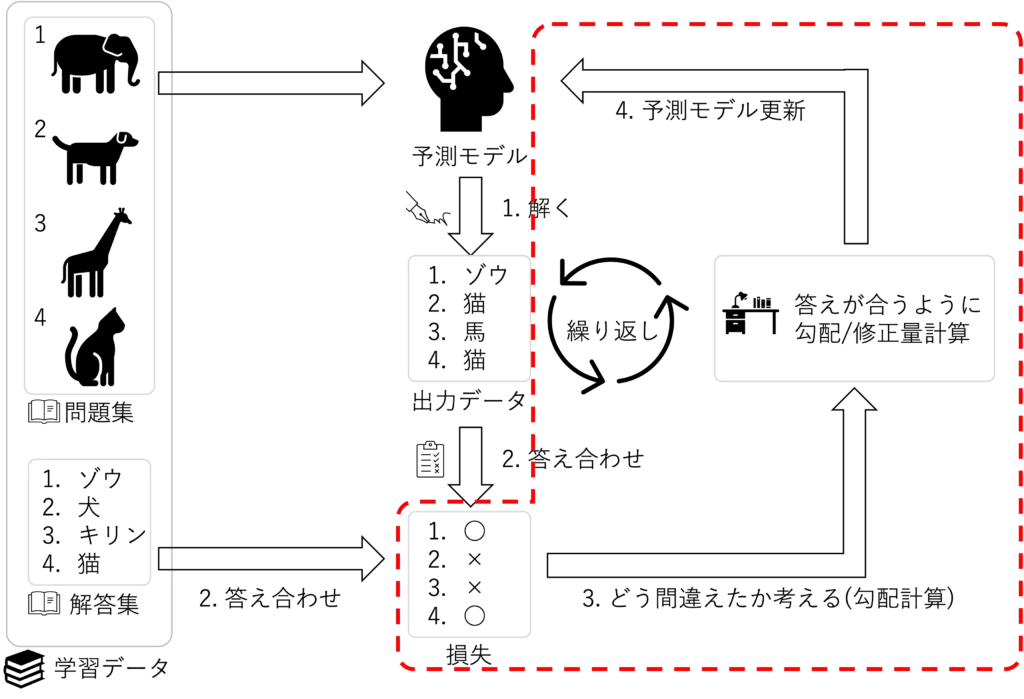
下記のコードが 実装になります
まず、ハイパーパラメータである 学習率の設定をしています
次にモデル、損失関数、最適化関数の設定です
損失関数のクロスエントロピー CrossEntropyLoss() は、多クラス分類タスクの損失関数として 一般的に使用されます(公式ドキュメント)
最適化アルゴリズムは、 optim.Adam()はAdam(Adaptive Moment Estimation)であり、機械学習モデルのパラメータを 最適化するための確率的勾配降下法の一種です(公式ドキュメント)
ここでの model.parameters() は、モデルのすべての学習可能なパラメータ(重みやバイアス)への参照を提供します
この parameters() メソッドは、 PyTorch モデルに固有のもので、モデルの各レイヤーに対応するパラメータを生成しますlr=learning_rate は、学習率を指定します
学習率は、オプティマイザーがパラメータをどれだけ更新するかを制御します
値が大きすぎると 学習が不安定になり、小さすぎると 学習が遅くなる可能性があります
# ハイパーパラメータの設定
learning_rate = 0.001
# モデルと最適化アルゴリズムの選択
model = SimpleCNN(num_classes)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)部品が揃ったので、モデルの学習をしていきます
それに合わせて、一回の学習の度に学習したモデルの結果として検証データで 損失と精度を出します
そうすることで、どのように学習して精度が上がったかを確認することができます
下のコードの解説をしていきます
最初のブロックは、何回学習をさせるかというハイパーパラメータ、エポックを設定しています
今回は 15回学習させています
次のブロックは、学習時と検証時 それぞれの損失と精度を保存しておく配列の初期化を行なっています
次のfor文から学習ループに入っています
予測モデルを学習モードにします
PyTorchには、モデルを学習モードと検証モードに切り替える機能を持っています
学習モードでは、学習時にドロップアウトなどのモデルに変化をつけることができます
今回はそのような操作はしませんが、今後慣れておくために学習モードへの変更を行なっておきます
次の入れ子になっているfor文ではミニバッチ毎で学習をしています
概念としては下図の通りの内容になっています
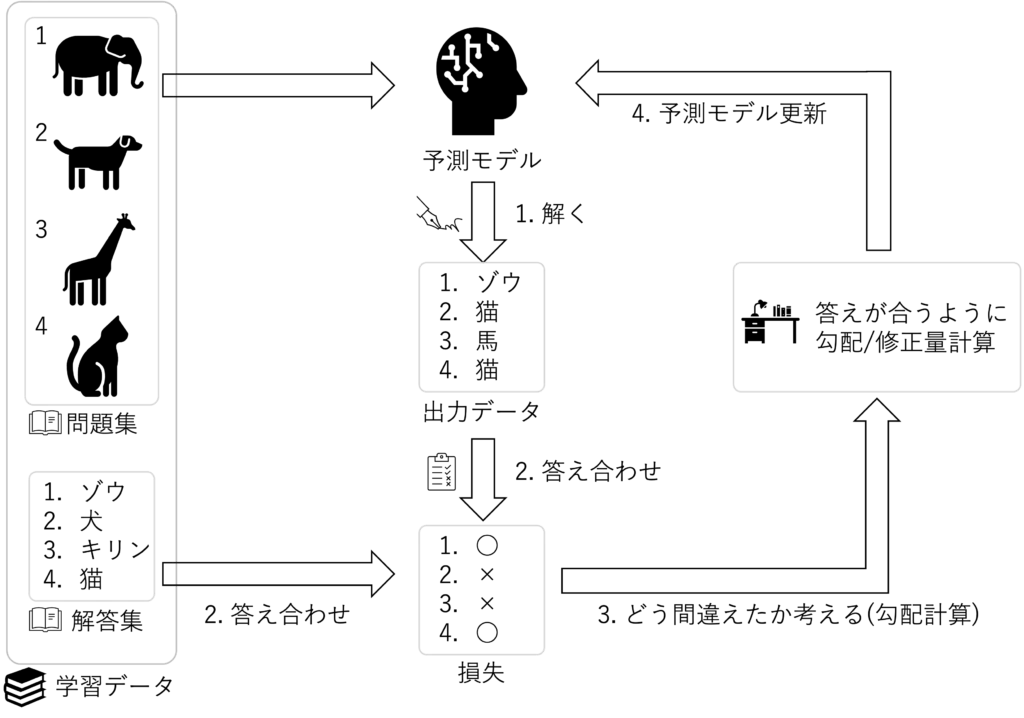
次のブロックでは、学習1回毎の損失、精度を出すために ミニバッチ毎の損失、精度を算出しています
ミニバッチのforループを抜けた後に、学習全体の損失、精度の平均化を行なっています
次に学習後の予測モデルを、検証データを使って損失と精度を算出します
モデルを model.eval() で 評価モードに切り替えます
そのあとは 基本的に学習の時と変わらないのですが、学習をする必要がないので勾配の計算をしないように with torch.no_grad()という with節の中でモデルを使用しています
そして、最後に学習、検証の損失、精度を保存用の配列に保存して、結果を出力する という構造になっています
# ハイパーパラメータの設定
num_epochs = 15
# プロット用のデータ記録配列
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []
for epoch in range(num_epochs):
# モデルを学習モードに変更
model.train()
running_loss = 0.0
correct = 0
total = 0
# ミニバッチ毎に学習を繰り返す
for i, data in enumerate(train_loader, 0):
# 学習データと正解ラベルを分割する
inputs, labels = data
# 勾配の初期化
optimizer.zero_grad()
# 1. モデルでの画像分類
outputs = model(inputs)
# 2. 正解ラベルと比較して損失を計算
loss = criterion(outputs, labels)
# 3. 勾配計算
loss.backward()
# 4. 最適化計算
optimizer.step()
# ミニバッチ毎で損失を累積
running_loss += loss.item()
# ミニバッチ毎の精度を算出、累積
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 学習データ全体の損失、精度を算出
train_loss = running_loss / (i + 1)
train_acc = correct / total
# 検証データに対する損失と精度
# モデルを評価モードに変更
model.eval()
correct = 0
total = 0
running_loss = 0.0
# 勾配計算をしないよう設定
with torch.no_grad():
for i, data in enumerate(valid_loader, 0):
inputs, labels = data
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_loss = running_loss / (i + 1)
val_acc = correct / total
# 学習、検証時の損失、精度を保存
train_loss_history.append(train_loss)
train_acc_history.append(train_acc)
val_loss_history.append(val_loss)
val_acc_history.append(val_acc)
print('Epoch {}: Train Loss: {:.4f}, Train Acc: {:.4f}, Val Loss: {:.4f}, Val Acc: {:.4f}'.format(epoch + 1,
train_loss,
train_acc,
val_loss,
val_acc))まずは、予測モデルが学習データと検証データで 損失の値がどう変化しているか確認してみましょう
下記コードで横軸が学習回数、縦軸が損失値の下図のグラフが描画されます
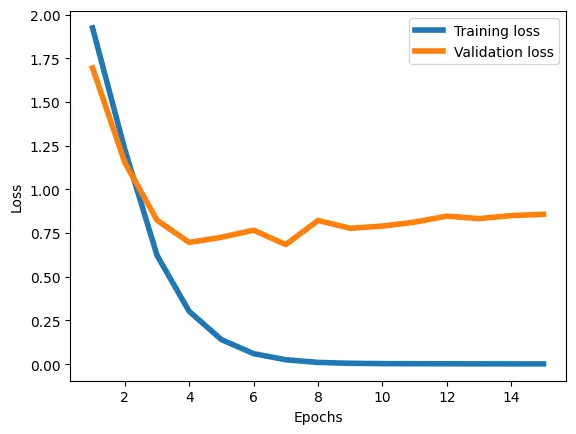
学習データでは 順調に損失が減っているのに対して、検証データは4回目くらいを境に損失値が減らなくなっています
それどことか、増加傾向にあるようにも見えます
過学習を起こしている状況です
epochs = range(1, num_epochs+1)
plt.plot(epochs, train_loss_history, lw=4, label="Training loss")
plt.plot(epochs, val_loss_history, lw=4, label="Validation loss")
plt.legend()
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()次に、予測モデルの精度も確認してみましょう
同様のコードで精度の確認ができます
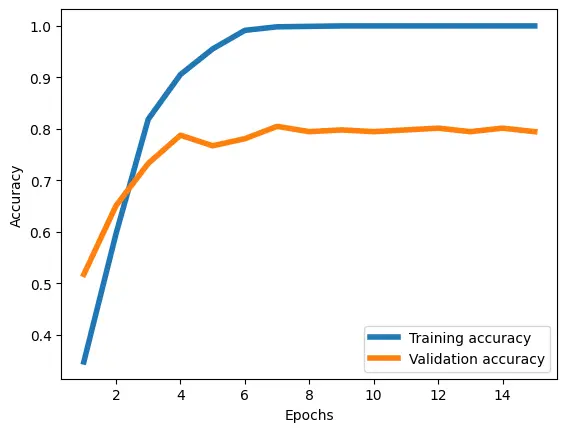
予測モデルは、学習データでは 学習を重ねる毎に増加していき、最終的に100%分類できるようになっています
一方、検証データは80%程度の精度に留まっています
この予測モデル、ハイパーパラメータでは80%の分類精度になるようです
逆に、この簡単な予測モデルでも10人の画像データを80%の精度で分類ができると捉えることもできます
plt.plot(epochs, train_acc_history, lw=4, label="Training accuracy")
plt.plot(epochs, val_acc_history, lw=4, label="Validation accuracy")
plt.legend()
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.show()今回はPyTorchを使って、LFWの画像データの うち10人の画像データを分類する予測モデルを構築しました
80%の精度で分類することができましたが、過学習が起きている状況になりました
過学習を抑制する方法はいくつか知られているので、今後紹介できればと思います


